Search is based on keyword.
Ex: "Procedures"
Do not search with natural language
Ex: "How do I write a new procedure?"
What's New in Katana 3.5
Introduction
This document describes notable changes introduced in Katana 3.5. These changes include:
- Geolib3-MT: This is the evolution of Geolib3 - Katana’s scene graph processing engine - to provide native multi-threaded scene graph expansion. The goals of the Geolib3-MT project are:
- To fully utilize the resources available on modern multi-core systems.
- To provide shared, intelligent caching technology to better manage memory resources during scene graph traversal.
- To reduce time-to-first-pixel (TTFP), allowing artists to efficiently iterate on shots and receive timely feedback.
- To improve artist productivity through improved UI performance.
- Analysis & Profiling Tools are provided, which help users debug the most time-costly Ops in a given Katana session.
- Optimized Key Workflows, improving performance of scenes where large numbers of locations are created.
- We now build and ship USD plug-ins based on USD 19.11, including the USD node types with some minor changes, as an opt-in set of resources in the plugins/Resources/Usd/ directory as part of a Katana installation. Documentation for how to opt into the USD plug-ins has been added to the Katana Developer Guide in form of the new Writing Plug-ins > Katana USD Plug-ins section. That section also outlines the differences between the USD plug-ins that now ship with Katana from those shipped in the Pixar USD repository.
- The experimental Monitor Layer feature is now integrated in the Viewer (Hydra) tab and can be turned on and off via a toggle button, toggled menu item, or keyboard shortcut (`). The Monitor Layer allows you to see a render overlayed onto the scene shown in the viewer.
- A new command-line option: --reuse-render-process has been added. When running Katana in batch mode with this option turned on, multiple frames will be rendered with a single instance of renderboot hosting the render plug-in, rather than launching a new renderboot process for every frame. Using this option can greatly improve performance of rendering sequences of frames, as the render plug-in and all other Katana plug-ins don't have to be reloaded for every frame.
Geolib3-MT Runtime
Katana node graphs, their Op trees and the scenes they subsequently create are incredibly flexible and varied. To optimally evaluate these scenes, an evaluation engine must be both efficient and flexible enough to handle the variety and complexity of scenes it’s possible to author using Katana. To meet the demands of increasingly complex and varied workloads,Geolib3-MT, the next generation of Katana scene graph processing engine, provides a greater degree of configuration, introspection and tuning options than previous versions of Geolib3. In this section we explore some of these options and how they can be leveraged to improve scene traversal performance.
Configuration
Geolib3-MT can be configured via the RenderSettings node. All Geolib3-MT options live under the sceneTraversal heading.

sceneTraversal.maxCores
Determines how many logical cores Geolib3-MT will use during scene traversal phase. Unlike previous versions, Geolib3-MT uses an internal thread pool to improve scene traversal time. The following diagram demonstrates the difference between Geolib3-MT and previous versions of Katana.
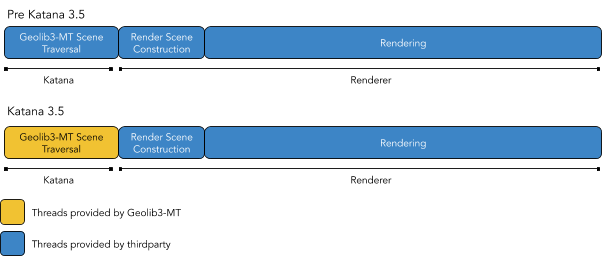
Note: The default value (0), causes Geolib3-MT to use all available logical cores on the host computer. Whilst the core Geolib3-MT processing engine scales well as the number of cores increases individual Ops within an Op tree may not exhibit the same scaling characteristics. Consequently, it is possible that an increase in threads result in an increase (not decrease) of scene traversal time. In this case, the new profiling tools available in Katana 3.5 can be used to identify these Ops and refactor/optimize their behaviour. The same is true of Ops marked “thread unsafe”, as these require the acquisition of a Global Execution Lock (GEL), which further limits scene traversal scalability.
sceneTraversal.opTreeOptimizations
Geolib3-MT can perform a pre-processing step in which it examines the topology of the Op tree to identify constructs that can be potentially optimised. One such optimisation is the collapsing of sequences of Ops of the same type into a single instance of that Op. There are a number of benefits to this,
- Reduced function call overhead - there is a small cost involved in scheduling an Op to cook a scene graph location. By combining chains of similar Ops it's possible to reduce this function call overhead.
- Reduced memory footprint - a chain of 10 Ops will occupy 10 separate cook results in the caching subsystem, a successfully collapsed Op chain will occupy only 1 cook result per location.
Note: The Op tree optimization pass is an experimental feature and is therefore turned off by default. It can be turned via the sceneTraversal.opTreeOptimizaions option on a RenderSettings node.
Further Information
The Op tree optimizer will attempt to collapse any chain of Ops of the same type if it calls GeolibSetupInterface::setOpsCollapsible() during the setup() call. Callers of this function must specify the name of an attribute which Geolib3 will pass to the Op's cook() call as an Op argument. This attribute will contain an ordered array of attributes (ordered upstream Op to downstream Op) containing the collapsed Ops' arguments. The Op is then able to deal with this "batch" Op argument as appropriate.
sceneTraversal.verboseLogging
To avoid a large number of informational messages filling the Render Log, Geolib3-MT does not log messages related to performance by default. These messages can be enabled by turning on the sceneTraversal.verboseLogging option on a RenderSettings node. Currently these messages include information about:
- Optimizations that couldn't be applied by the Op tree optimizer, if enabled.
- Memory used by the caching subsystem following a cache eviction.
sceneTraversal.cache Group
Geolib3-MT includes a number of settings to control the behaviour of the caching subsystem. The caching subsystem is responsible for the storage and retrieval of previously cooked scene graph locations, known as "cook results". These settings can be modified from the RenderSettings node on a project-by-project basis. Sensible defaults have been provided based on testing against production scale scenes. Further information about each of the settings is provided below,
- sceneTraversal.cache.cacheEviction - turned on by default. If turned off, no cook results will be evicted from the cache. Whilst initially it might seem counter-intuitive to turn off cache eviction, there may exist some scenes where this is appropriate. In particular, when the size of the scene and data structures required by the renderer can comfortably fit into memory; even larger scenes could benefit to some degree, as once the scene generation phase of rendering is complete the memory pages occupied by Geolib3-MT's cook results will no longer be accessed and hence be eligible for paging to disk, as these pages won't be re-paged to main memory during rendering the performance penalty is minimal.
- sceneTraversal.cache.cacheSoftLimit - if cache eviction is turned on the soft limit governs how many cook results will be stored in local caches before entries are evicted using a least recently used eviction policy.
Note: Whilst these entries may be evicted from a local cache they may be shared amongst a number of other local caches or the central (shared cache). In which case, the entries' memory won't immediately be reclaimed.
- sceneTraversal.cache.collectionFrequency - if cache eviction is turned on the collection frequency governs the time, in milliseconds, between collection cycles. During a collection cycle Geolib3-MT will gather all cache entries evicted since the previous collection cycle and if the cook result is no longer used, evict and reclaim the memory for the cook result.
Further Information
Caching, and the trade-off between memory usage and time to first pixel can have a significant impact on the performance of scene traversal time and rendering. Using the settings provided by Geolib3-MT it's possible to tune the memory footprint during the scene traversal phase of rendering. Here are some considerations when deciding to experiment with these scenes,
- Consider the maximum depth of the scene graph and Op tree - the cache soft limit controls the size of the recently used cook results on a per thread basis. This means any locations cooked on a particular thread or, any locations accessed during the cooking process (such as via getAttr()) will be stored in the local cache and subject to eviction based on the value of sceneTraversal.cache.cacheSoftLimit.
- Reducing the collection frequency interval will cause more aggressive eviction of cook results leading to a reduced memory footprint but potentially at the cost of scene traversal time.
sceneTraversal.useCachePrepopulation
If turned on, Geolib3-MT will perform a traversal of the scene graph populating an internal cache. The extent of this traversal can be controlled by the settings under sceneTraversal.cachePrepopulation and are explained below,
- sceneTraversal.cachePrepopulation.preCookSourceOps - turned off by default, if turned on Geolib3-MT will first fully traverse the scene generated by any source Op found in the Op tree. A source Op is classed as any Op with no inputs. This setting can provide benefits when loading in geometry caches or other asset types. Empirical tests have found that source Ops are typically followed by some form of prune operation, as a result, in these cases the pre cooking the source Op can generate more scene graph locations than is required which can lead to increased memory consumption and traversal times.
- sceneTraversal.cachePrepopulation.preCookKeyOps - turned on by default, Geolib3-MT will identify Ops within the Op tree that can be evaluated in parallel. An obvious example of this is the Merge Op, in this case Geolib3-MT will evaluate each branch in parallel which can improve reduce scene traversal times.
- sceneTraversal.cachePrepopulation.preCookAllLocations - turned on by default, Geolib3-MT will cook all remaining scene graph locations, fully expanding the scene.
Based on the values of the above settings, on completion of the cache prepopulation phase the Geolib3-MT cache will have been pre-populated with either the whole scene graph or a subsection of it. Geolib3-MT has been optimised to provide efficient access to renderer plug-ins via the existing FnScenegraphIterator API to this cache. This cache is a scalable, thread safe cache, as such we encourage renderer plug-in writers to access this cache concurrently to improve the performance of the scene build phase.
Note: If the Geolib3-MT cache is not fully populated, cache access (via FnScenegraphIterator) will result in a cache miss. In this case the requested location will be cooked using the calling thread.
API Improvements
Various APIs have been extended to improve performance and memory management
- GeolibRuntime::finalize() and FnScenegraphIterator::finalizeRuntime() methods for use by renderer plug-ins -- Typically, after traversing the scene, renderer plug-ins are now able to explicitly state that the Geolib3 Runtime will not be needed again. The Runtime will purge memory, and cease further computation.
- FnAttribute::getSize() -- This function returns the size of the memory that was dynamically allocated for a specific attribute. For group attributes, the size represents the sum of the sizes of all the child attributes, as well as the length of the child names. If a group attribute contains duplicate references of the same attribute instance, the size of such attribute will be accounted just as many times as it appears in the group.
- AttributeKeyedCache contains a thread-efficient alternative. This template class has been reimplemented in terms of TBB’s concurrent hash map. Users that do not have TBB available can still use the mutexed version by defining ATTRIBUTEKEYEDCACHE_NO_TBB before including the header file.
- GeolibSetupInterface::setOpsCollapsible(). If set, this indicates to Geolib3-MT that this type of Op supports collapsing. In a future release Geolib3-MT will use this information to identify chains of similar Ops and collapse them to a single cook() call.
- kFnKatGeolibThreadModeGlobalUnsafe has been deprecated. All Ops should either be thread-safe or implement their own internal locking.
-
Some new functions named setup(), cleanup() and setRootIterator() have been added to the RenderBase class for renderer plug-ins in the plugin_apis/include/FnRender/plugin/RenderBase.h header. These enable render plug-ins to render multiple frames in a single instance instead of creating a new instance of the plug-in for each frame.
Analysis & Profiling Tools
Geolib3-MT Profiling
Geolib3-MT adds a new render type, called Preview Render with Profiling, designed to help track down performance problems in scene traversal. This performs a normal Preview Render, but also captures information about which Ops have run, the amount of CPU used by them to cook locations, and the amount of memory used for attributes and Lua scripts.
A Preview Render with Profiling outputs profiling data in two places:
- A summary report in the Render Log, containing total CPU time and memory used, as well as the 10 most expensive Ops.
- A JSON file written to disk containing raw profiling data, described below.
Starting a Preview Render with Profiling
A Preview Render with Profiling can be started from the same menu as any other render, by choosing the Preview Render with Profiling command.
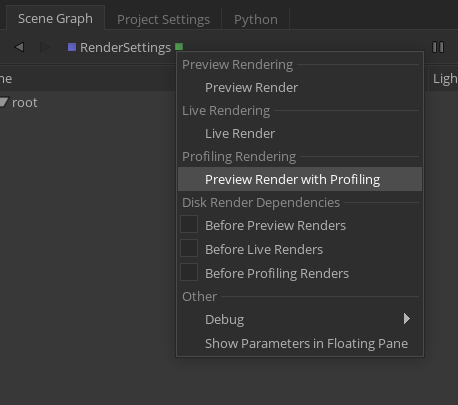
This option will be available for any renderer that already supports a Preview Render, and requires no additional work on the part of the renderer. If the renderer implements the finalize() method of the Geolib3-MT Runtime, these profiling reports will be created when the runtime is finalized; otherwise reports will be written when the render finishes.
What information is captured?
The name, type and numerical ID of the Op. Each Op has name, type and a unique numeric ID. For example, an OpScript Op may have name op74, type OpScript.Lua and ID 77. Note the name and ID need not correlate.
The name and type of the Katana node that spawned the Op. In cases where an Op is spawned directly by a Katana node, the name and type of that node are recorded. In cases where the Op was created implicitly, the node name will equal _NoName_ and the type will equal _NoType_. This occurs, for example, with MaterialFilenameResolve Ops: these Ops are created implicitly when a filename needs to be resolved, so no Katana node is identified as the creator.
Note: If sceneTraversal.opTreeOptimizations is turned on and chains of Ops are collapsed, node name and type will be replaced with a string generated from the chain. If the chain has length t, formed of Ops of type opType, where Op k is named ok and is generated by a Katana node named ni, the general form of the string will be:
cop(o0(n0)->o1(n1)->...->ot(nt))
Note however that the format of this string is not guaranteed to remain fixed.
The total CPU time that Op spent cooking locations. Each Op will cook many locations, and the time spent doing this, across all scene traversal threads, is accumulated. Thus, CPU time should scale with number of scene traversal threads when a scene is traversed in parallel. If this is not the case, there may be a thread-unsafe Op upstream of the Op in question.
The memory footprint of that Op. Each Op must allocate memory to cook locations, and the memory total per Op is aggregated. At present, only the following allocations are recorded:
- Allocations made by the FnAttribute library, to store attributes of cooked locations;
- Allocations made by the Lua interpreter while executing OpScripts; and
- Allocations made to store CookResults in the cache.
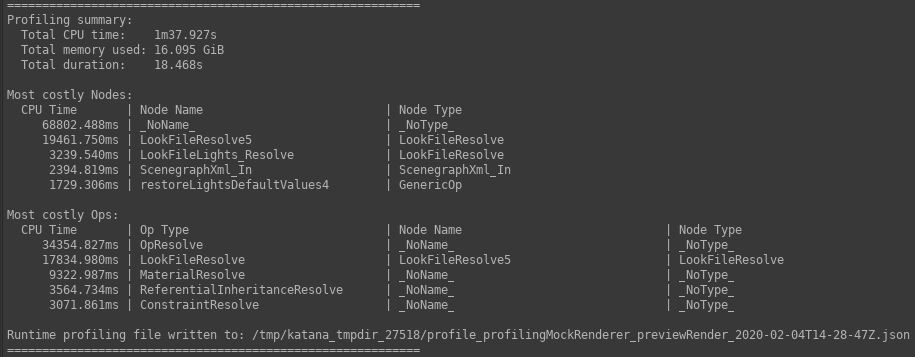
Profiling Summary Report
A summary report will be written to the Render Log upon completion of a Preview Render with Profiling. This report is intended to give a high-level overview of the profile data, and contains:
- The total CPU time, summed across all Ops;
- The total memory footprint, summed across all Ops; and
- The slowest five Ops by CPU time.
The relevant section of an example Render Log is shown below:
Profiling JSON File
In addition to the summary report, a JSON file containing the raw profiling data is written to disk. The directory it is written to is determined by the --profiling-dir command-line option; if this is not set, it will be written to the temporary directory for the Katana session. If this directory does not exist, it will be created (if filesystem permissions allow). The filename takes the following format:
profile_<renderer>_previewRender_<datetime>.json
where:- <renderer> is the name of the render plug-in, e.g. dl for 3Delight;
- <datetime> is the ISO8601 timestamp from when the render was started.
The file contains a single JSON object with the following properties:
| Property | Type | Description | Example |
|---|---|---|---|
| timestamp | string | ISO8601 timestamp at which the profile file was written. | 2019-10-11T09:37:06Z |
| renderer | string | Name of the render plug-in. | dl |
| renderMethodName | string | Name of the render method; currently always “previewRender”. | previewRender |
| environment | object |
An object containing values of various environment variables, including:
| {
“KATANA_RELEASE”: “3.5v1”,
“KATANA_ROOT”: /opt/foundry/katana3.5”,
“KATANA_RESOURCES”: “<unset>”
} |
| profileMode | string | Name of the profile mode; currently always “basic”. | basic |
| ops | array | Array of objects describing resources consumed by each Op. | See below. |
| numOps | number | Length of the Ops array. | 78 |
| wallTime | number | Wall-clock time in seconds between render start and the profiling file being written; if the renderer implements finalize(), this equates to scene traversal time. | 46.85064 |
| cpuTime | number | Sum of CPU time for all Ops, in seconds. | 91.39238 |
| memoryUsed | number | Sum of memory footprints for all Ops, in bytes. | 10728607911 |
The ops property contains an array of objects of the following format, one for each Op that was executed during scene traversal.
| Property | Type | Description | Example |
|---|---|---|---|
| opId | number | The unique integer identifier for the Op. | 23 |
| opName | string | The unique name of the Op. | op223 |
| opType | string | The type of the Op. | AttributeSet |
| nodeName | string | The name of the Katana node responsible for creating this Op, or _NoName_ if the Op was created implicitly. | RenderSettings_SetSamples |
| nodeType | string | The type of the Katana node responsible for creating this Op, or _NoType_ if the Op was created implicitly. | RenderSettings |
| cpuTime | number | The total time this Op spent cooking locations across all threads, in seconds. | 0.54512136 |
| memoryUsed | number | The total memory footprint, as defined above, this Op used while cooking locations, in bytes. | 185378321 |
- Command-Line Tools for Op Tree Debugging -- A new command-line tool, scenewalker, is available to aid Op development, scene debugging and performance analysis. scenewalker can be configured to traverse an Op tree using a configurable number of cores, or traverse only a specific location and output raw attribute data from the scene graph.
Experimental Features
The environment variable KATANA_EXPERIMENTAL_MONITOR_OVERLAY is no longer used. The Monitor Layer feature is now an experimental feature of the Viewer (Hydra) tab and can be turned on and off via a toggle button, toggled menu item, or keyboard shortcut (`).
Reusing the Render Process in a Batch Render
A new mode for optimizing the launch of the renderboot process that hosts the render plug-in has been added to Katana's batch mode, which can be turned on by passing the new --reuse-render-process command-line option to the Katana executable (in addition to --batch). When running Katana in batch mode with this option turned on, multiple frames will be rendered with a single instance of renderboot hosting the render plug-in, rather than launching a new renderboot process for every frame. Using this option can greatly improve performance of rendering sequences of frames, as the render plug-in and all other Katana plug-ins don't have to be reloaded for every frame.
Note: Render plug-ins have to be recompiled against the Katana 3.5v1 Rendering API in order to support the --reuse-render-process command-line option in batch mode.
Some new functions named setup(), cleanup() and setRootIterator() have been added to the RenderBase class for renderer plug-ins in the plugin_apis/include/FnRender/plugin/RenderBase.h header. These enable render plug-ins to render multiple frames in a single instance instead of creating a new instance of the plug-in for each frame.
Other Notable Feature Enhancements
ID 55592 / BZ 27736 - A new -V / --verbose command-line option for controlling the level of verbosity of logging informational messages has been added to the Katana executable:
-V LEVEL, --verbose=LEVEL The level of verbosity of logging informational messages. Defaults to 1. Set to 0 to suppress most informational messages.ID 280477 - It is now possible to copy the textual representation of selected items from deferred group tree widgets in the Attributes tab to the clipboard. This type of widget is used, for example, for the lightList group attribute at /root/world and for the material.nodes group attribute on material locations that represent Network Materials.
Sorry you didn't find this helpful
Why wasn't this helpful? (check all that apply)
Thanks for your feedback.
If you can't find what you're looking for or you have a workflow question, please try Foundry Support.
If you have any thoughts on how we can improve our learning content, please email the Documentation team using the button below.
Thanks for taking time to give us feedback.