検索はキーワードに基づいています。
例:「手順」
自然言語で検索しないでください
例:「新しいプロシージャを作成するにはどうすればよいですか?」
並行性に配慮したシーンの作成
シーンのスループットとボトルネックの特定方法を理解する
Geolib3-MTでは、システムスループットは、1秒間に処理されるシーングラフの位置の数として定義されます。特定のシーングラフの処理において、瞬間的な目標は、Geolib3-MTの処理スループットを維持または増加させることです。
場所のボトルネック
典型的なシーンでは、一部のシーングラフの場所は他の場所よりも計算に時間がかかります。これは、シーングラフ処理の通常の予想される動作です。ただし、これらの計算コストの高い場所は、後続の場所がその結果に依存する場合、システム全体のボトルネックになる可能性があります。
具体例を示すために、次のスクリーンショットでは、OpScript_lsysStringはシーングラフの場所/ root / world / geo / lsysでコストのかかるLシステム記述を生成します。ノードOpScript_lsystemはこの記述を処理して、ツリーのグラフィカルな表現を構築します。
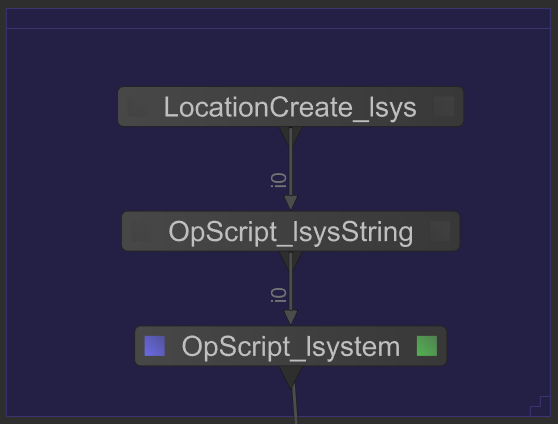
OpScript_lsystemの動作はOpScript_lsysStringに完全に依存しているため、OpScript_lsysStringによって/ root / world / geo / lsysが計算されるまで、シーングラフ全体の処理が停止します。このツリーを処理するときの結果のスループットは次のようになります。
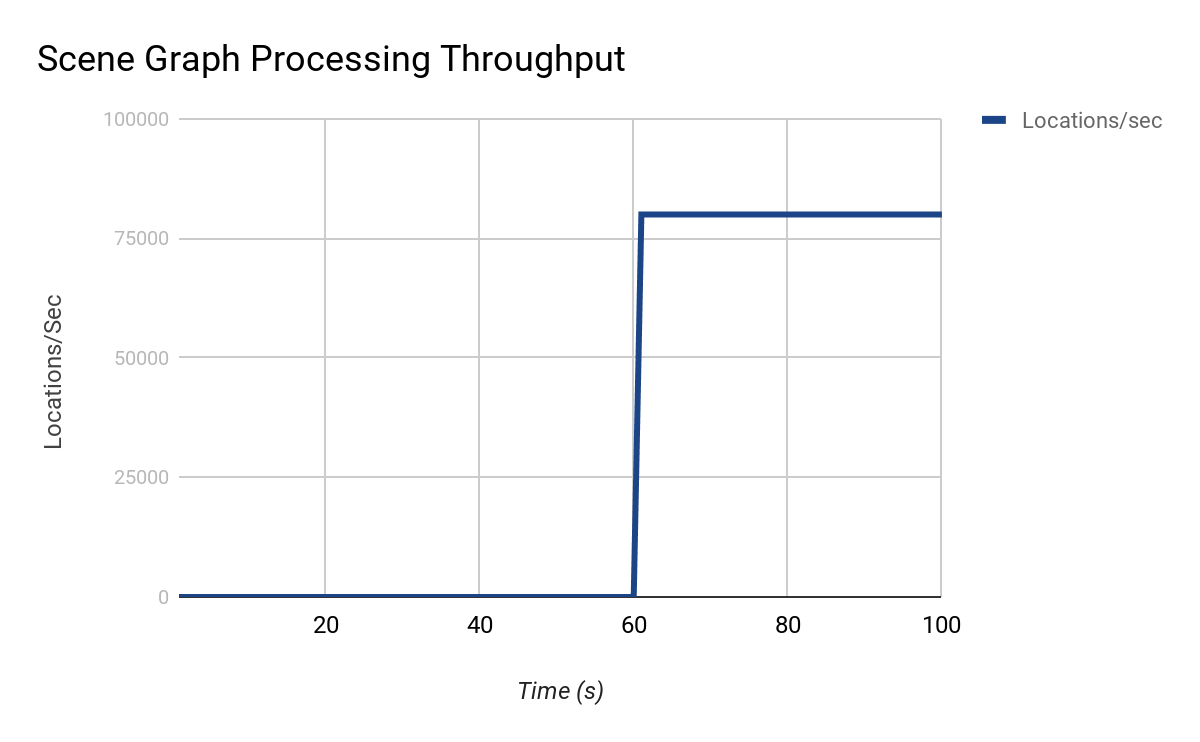
最初の検査では、0〜60秒の処理がミューテックスまたはシリアルコードによって制限されていると想定するのが妥当です。ただし、前述のように、これは実際には非常にコストのかかる場所であり、シーンの残りの部分が依存しています。このようなシーンのボトルネックに対処するためのオプションは何ですか?
まず、付属のOpツリープロファイリングツールを使用できます。 Katana 3.5シーン内の高価なOpsを特定します。この情報を使用して、高価なOpのパフォーマンスを最適化することができます。これらのOpsの最適化は、実行している作業の性質に大きく依存します。しかし、他の最適化タスクと同様に、まず最適化ターゲットを特定し、測定し、リファクタリングし、再測定します。
Opツリー内の1つまたは2つの主要なOpを最適化するだけで、ボトルネックを完全に除去できる場合があります。これは、Luaオブジェクトの作成を慎重に使用すると、Lシステム記述を計算する時間が大幅に短縮された上記の例の場合です。ただし、場合によっては、単にコストがかかる操作を受け入れる必要があります。この場合、シーン処理のスループットを維持するのに役立つオプションは何ですか?
次のステップは、処理の問題自体を調べることです。それを、シーングラフの場所によってリンクまたはインデックス付けできる、より小さな論理的なチャンクに分解できるかどうか。シーングラフトポロジを効果的に使用して、各子が並行して処理できる作業のサブセクションを表す並列処理タスクグラフを表します。
たとえば、最初の1000個の素数を計算する必要があるとします。/ root / world / geo / data / primesの場所で各プライムを順番に計算してIntAttributeとして保存するOpを作成できます。または、/ root / world / geo / data / primesの下に1000個の子を作成するOpを作成し、各子の位置をプライムシリーズのインデックスとして使用することもできます。それらの子では、Opはシリーズのその時点で素数を計算します。この例では、Geolib3-MTはシーングラフ内で利用可能な並列処理を利用して、各子が並列に実行されるようにスケジュールできます。
このアプローチの拡張は、計算集約的な作業がOpツリーを使用して分割され、結果がMergeノードを使用して照合される、計算的に独立したシーングラフのUse Mergeブランチでも提供されます。
最後に、シーントラバーサルパターンの知識を活用できます。Geolib3-MTはシーンの幅広の最初の拡張を完了します。したがって、計算コストの高いシーングラフの場所が存在する場合は、他の多数の子と並行して処理できるシーングラフの場所の下に配置することを検討してください。次に、1つの場所が調理に時間がかかる場合がありますが、他の場所(実際には、シーングラフの残りの部分)の評価が妨げられることはありません。
処理能力
シーンのスループットは、処理能力によって制限されます。使用可能なCPUコアよりも多くのシーングラフの場所が処理される場合、使用可能なコアの完全な使用率(飽和)と、処理を待機しているシーングラフの場所のバックログが表示されます。一般に、コアを追加すると、シーングラフの処理時間が短縮されます。
逆に、利用可能なコンピューティングリソースがシーングラフの場所を処理できる場合、新しい場所が知られるよりも速くなるか、シーンに単に十分な大きさが含まれない場合(「十分な大きさ」は、OpツリーのOps各シーングラフの場所で)すべてのコアを利用し続けるためのシーングラフの場所の数は、それらのコアを完全に利用するために利用可能なコアの数を減らすことから得られる場合があります。パフォーマンスの観点から、これは、L2 / L3キャッシュのパフォーマンスを潜在的に改善する可能性のあるCPUピニング戦略と組み合わせると有益な場合があります。
ミューテックスおよびその他の同期プリミティブの間接的な使用を特定する
コードのシリアル化された実行を強制するミューテックスおよびその他の同期プリミティブは、シーングラフの評価パフォーマンスに大きな悪影響を与える可能性があります。独自のコードでミューテックスを特定するのは簡単ですが、サードパーティのコードやライブラリではより問題が多い場合があります。
シーンのOpsがミューテックスまたはクリティカルセクションにラップされたコードを間接的に呼び出している可能性のある症状は次のとおりです。
- シーン処理に使用できるスレッド/コアの数を増やすと、シーングラフの拡張と最初のピクセルまでの時間が減少するのではなく、増加します。
- スレッド安全でないOpが呼び出されたことを示すレンダーログのメッセージ。
- シーン処理には複数のスレッド/コアを使用できますが、実際に使用されるコアは1つまたは2つのみです。
Alembic HDF5から小川
具体的な例を提供するために、Alembicキャッシュは、HDF5と、並列シーントラバーサルをサポートするように設計された新しい小川形式の2つの形式で保存できます。メッセージは出力されませんがRender Log HDF5形式のキャッシュを読み取る場合、シーンの走査時間は大幅に遅くなり、スレッドを追加するとパフォーマンスが低下する可能性があります。約140kの場所を持つテストシーンで、既存のHDF5キャッシュを小川に変換すると、32コアのタスクプールを処理できるシーントラバーサル時間が26.2秒から3.9秒に短縮されました。
Alembicライブラリには、AlembicファイルをHDF5からOgawaに変換するabcconvertというユーティリティがあります。このユーティリティはソースからビルドする必要があります。このソースはで見つけることができますここに、リポジトリのルートにある指示とともに。
ビルド後、abcconvertは次のようにコマンドラインから使用できます。
- cd / path / to / build / directory
- abcconvert -toOgawa -in <入力ファイル> <出力ファイル>
入力ファイルが既にOgawa形式の場合、abcconvertは何もしません。
申し訳ありませんが、これは役に立ちませんでした
なぜこれが役に立たなかったのですか? (当てはまるもの全てをご確認ください)
ご意見をいただきありがとうございます。
探しているものが見つからない場合、またはワークフローに関する質問がある場合は、お試しくださいファウンドリサポート。
学習コンテンツを改善する方法についてご意見がある場合は、下のボタンを使用してドキュメントチームにメールしてください。
フィードバックをお寄せいただきありがとうございます。