検索はキーワードに基づいています。
例:「手順」
自然言語で検索しないでください
例:「新しいプロシージャを作成するにはどうすればよいですか?」
Geolib3-MTプロファイリング
Geolib3-MTは、新しいレンダリングタイプを追加します。 Preview Render with Profiling、シーントラバーサルのパフォーマンスの問題を追跡するのに役立つように設計されています。これは通常のPreview Render、ただし、どのOpが実行されたか、ロケーションをクックするためにそれらが使用したCPUの量、および属性とLuaスクリプトに使用されたメモリの量に関する情報もキャプチャします。
プロファイリングを使用したプレビューレンダリングは、プロファイリングデータを2つの場所に出力します。
- の要約レポートRender Log、使用された合計CPU時間とメモリ、および最も高価な10個のOpが含まれます。
- 生のプロファイリングデータを含むディスクに書き込まれたJSONファイル。
プロファイリングを使用したプレビューレンダリングの開始
A Preview Render with Profiling他のレンダーと同じメニューから開始できます:
- レンダリング元のノードを右クリックします。
- クリックPreview Render with Profilingメニューから。
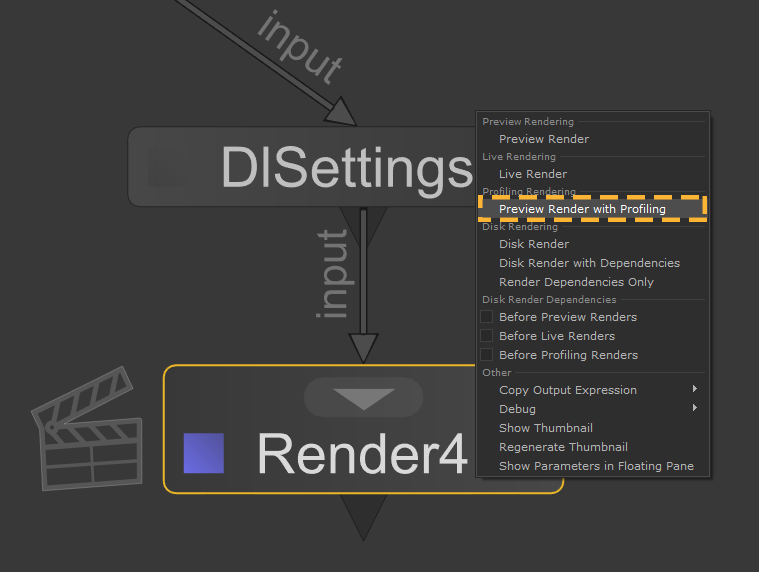
このオプションは、既にサポートしているすべてのレンダラーで利用可能ですPreview Render、レンダラー側での追加作業は必要ありません。レンダラーがfinalize() Geolib3-MTランタイムのメソッド、これらのプロファイリングレポートは、ランタイムが終了したときに作成されます。そうでない場合、レンダリングが終了するとレポートが書き込まれます。
中にプロファイリングデータをキャプチャするオーバーヘッドPreview Render with Profiling最小限であり、通常に比べて大幅な減速はありませんPreview Render。
収集される情報
A Preview Render with Profilingシーントラバーサル中に実行される各Opの次の情報をキャプチャします。
- のname、 typeそしてnumerical IDの
各Opには名前、タイプ、一意の数値IDがあります。たとえば、 OpScript Opには名前がありますop74、タイプOpScript.Lua;とID 77。注意: のnameそしてID相関させる必要はありません。
- のnameそしてtypeのKatana Opを生成したノード。
Opが直接生成される場合Katanaノード、 nameそしてtypeそのノードの記録されます。Opが暗黙的に作成された場合、ノード名は次のようになります_NoName_タイプは等しくなります_NoType_。これは、たとえばMaterialFilenameResolveこれらのOpsとしてのOpsは、ファイル名を解決する必要があるときに暗黙的に作成されるため、no Katanaノードは作成者として識別されます。注意: もしsceneTraversal.opTreeOptimizations有効化され、Opsのチェーンが折りたたまれ、ノードnameそしてtypeチェーンから生成された文字列に置き換えられます。チェーンに長さがある場合t、タイプのOpsで形成opType 、 どこOp kという名前ですokによって生成されますKatana指定されたノードn k、文字列の一般的な形式は次のとおりです。ただし、この文字列の形式が固定されたままであるとは限りません。
- のtotal CPU timeそのOpは場所の調理に費やしました。
各Opは多くの場所をクックし、すべてのシーントラバーサルスレッドでこれを行うために費やされた時間が累積されます。シーンが並行してトラバースされる場合、CPU時間はシーントラバーサルスレッドの数に比例します。そうでない場合は、問題のOpの上流にスレッドセーフでないOpがある可能性があります。 - のmemory footprintその操作の
各Opはメモリをクックの場所に割り当てる必要があり、Opごとのメモリの合計が集計されます。
現在、次の割り当てが記録されています。
- によって行われた割り当てFnAttributeライブラリ、調理済みの場所の属性を保存します。
- によって行われた割り当てLua OpScriptsの実行中のインタープリター。
- 保管する割り当てCookResultsキャッシュ内。
プロファイリング概要レポート
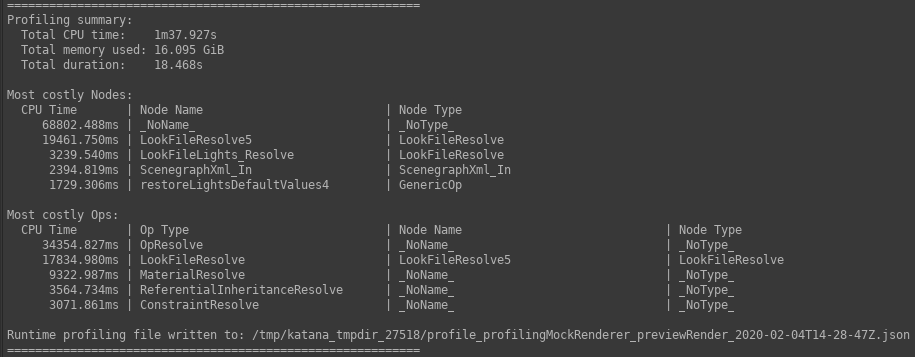
要約レポートがRender Log完了時にPreview Render with Profiling。このレポートは、プロファイルデータの概要を提供することを目的としており、次のものが含まれています。
- すべてのOpsで合計された合計CPU時間。
- すべてのOpsで合計された合計メモリフットプリント。
- CPU時間による最も遅い5つのOp。
|
|
| 例の関連セクションRender Log. |
JSONファイルのプロファイリング
概要レポートに加えて、生のプロファイリングデータを含むJSONファイルがディスクに書き込まれます。書き込まれるディレクトリは、 --profiling-dirコマンドライン引数。これが設定されていない場合、一時ディレクトリに書き込まれますKatanaセッション。このディレクトリが存在しない場合は、ファイルシステムのアクセス許可が許可されている限り、作成されます。ファイル名の形式は次のとおりです。
profile_ <renderer> _previewRender_ <datetime> .json
どこ:
- <renderer>はレンダリングプラグインの名前です(例:3Delightのdl)。
- <datetime>は、レンダリングが開始されたときからのISO8601タイムスタンプです。
ファイルには、次のプロパティを持つ単一のJSONオブジェクトが含まれます。
|
物件 |
タイプ |
説明 |
例 |
|
タイムスタンプ |
ストリング |
プロファイルファイルが書き込まれたISO8601タイムスタンプ。 |
2019-10-11T09:37:06Z |
|
レンダラー |
ストリング |
レンダリングプラグインの名前。 |
dl |
|
renderMethodName |
ストリング |
レンダリングメソッドの名前。現在は常にpreviewRender。 |
previewRender |
|
環境 |
対象 |
以下を含むさまざまな環境変数の値を含むオブジェクト。
|
{ 「KATANA_RELEASE」:「3.5v1」、 「KATANA_ROOT」:/opt/foundry/katana3.5v1」、 「KATANA_RESOURCES」:「<未設定>」 } |
|
profileMode |
ストリング |
プロファイルモードの名前。現在は常にbasic。 |
基本的な |
|
ops |
アレイ |
各Opによって消費されるリソースを記述するオブジェクトの配列。 |
下の表をご覧ください |
|
numOps |
数 |
Ops配列の長さ。 |
78 |
|
wallTime |
数 |
レンダリングの開始からプロファイリングファイルの書き込みまでの秒単位の実時間。レンダラーが実装する場合finalize()、これはシーンの横断時間に相当します。 |
46.85064 |
|
cpuTime |
数 |
すべてのOpsのCPU時間の合計(秒単位)。 |
91.39238 |
|
使用メモリ |
数 |
すべてのOpのメモリフットプリントの合計(バイト単位)。 |
10728607911 |
opsプロパティには、シーントラバース中に実行された各Opに1つずつ、次の形式のオブジェクトの配列が含まれます。
|
物件 |
タイプ |
説明 |
例 |
|
opId |
数 |
Opの一意の整数識別子。 |
23 |
|
opName |
ストリング |
オペレーションの一意の名前。 |
op223 |
|
opType |
ストリング |
オペレーションのタイプ。 |
AttributeSet |
|
nodeName |
ストリング |
の名前KatanaこのOpの作成を担当するノード、または_NoName_ Opが暗黙的に作成された場合。 |
RenderSettings_SetSamples |
|
nodeType |
ストリング |
のタイプKatanaこのOpの作成を担当するノード、または_NoType_ Opが暗黙的に作成された場合。 |
RenderSettings |
|
cpuTime |
数 |
このOpがすべてのスレッドで場所をクッキングするのに費やした合計時間(秒単位)。 |
0.54512136 |
|
使用メモリ |
数 |
上記で定義されているように、ロケーションのクッキング中にこのOpが使用した合計メモリフットプリント(バイト単位)。 |
185378321 |
プロファイル結果の分析
結果をさまざまな方法でソートおよびグループ化するために、Python 2.7スクリプトが含まれています。このスクリプトは次の場所にあります。
$ KATANA_ROOT / extras / Profiling / analyzeProfilingRenderResults.py
次のように、コマンドラインからこのPythonスクリプトを呼び出すことができます。
cd $ KATANA_ROOT / extras / Profiling
python analyzeProfilingRenderResults.py /path/to/results/file.json <オプション>
次のコマンドラインオプションを使用できます。
|
- 助けて |
ヘルプテキストを表示して終了します。 |
|
-並べ替えFIELDNAME |
FIELDNAMEで結果をソートします。FIELDNAMEは、opId、opName、opType、nodeName、nodeType、cpuTime、またはmemoryUsedのJSONプロパティ名のいずれかです。 |
|
--reverse、-r |
結果を逆順に並べ替えます。 |
|
--group-by FIELDNAME |
FIELDNAMEで結果をグループ化します。FIELDNAMEは、opId、opName、opType、nodeName、nodeType、cpuTime、またはmemoryUsedのいずれかのJSONプロパティ名です。 |
|
-人間が読める形式、-h |
メモリの合計を人間が読める単位で印刷します(つまり、バイトではなくKiB、MiBなど)。 |
|
--limit LIMIT、-l LIMIT |
グループ化およびソート後、出力を最初のLIMIT行に制限します。 |
|
--columns COLUMNS |
指定された列のみを出力します。COLUMNSはJSONプロパティ名opId、opName、opType、nodeName、nodeType、cpuTimeまたはmemoryUsedのコンマ区切りリストです。 |
スクリプトは、結果のASCIIテーブルを出力しますstdout、要求に応じてグループ化およびソートされます。もし--sort-by設定されていない場合、結果はソートされますopId。もし--group-by設定されていない場合、グループ化は行われません。
注意: でグループ化する場合nodeName、名前付きのすべての結果_NoName_グループ化されます。同じことが当てはまりますnodeType。
コマンドラインオプションの次の組み合わせは、開始するのに役立つ場合があります。
|
--group-by opType --sort-by cpuTime |
CPUを最も多く使用するOpタイプを見つけます。 |
|
--group-by nodeName --sort-by cpuTime |
どのを見つけるKatanaノードは最もCPUを集中的に使用します。 |
|
--group-by nodeType --sort-by memoryUsed |
どのを見つけるKatanaノードタイプは、最大のメモリフットプリントを占めます。 |
申し訳ありませんが、これは役に立ちませんでした
なぜこれが役に立たなかったのですか? (当てはまるもの全てをご確認ください)
ご意見をいただきありがとうございます。
探しているものが見つからない場合、またはワークフローに関する質問がある場合は、お試しくださいファウンドリサポート。
学習コンテンツを改善する方法についてご意見がある場合は、下のボタンを使用してドキュメントチームにメールしてください。
フィードバックをお寄せいただきありがとうございます。