동시성 친화적 인 장면 구성
장면 처리량 이해 및 병목 현상 식별 방법
Geolib3-MT에서 시스템 처리량은 초당 처리되는 장면 그래프 위치 수로 정의됩니다. 주어진 장면 그래프를 처리 할 때 순간 순간 목표는 Geolib3-MT 처리 처리량을 유지하거나 늘리는 것입니다.
위치 병목
일반적인 장면에서 일부 장면 그래프 위치는 다른 장면보다 계산 시간이 더 오래 걸리며 이는 장면 그래프 처리의 정상적인 동작입니다. 그러나 이처럼 값 비싸고 계산하기 쉬운 위치는 후속 위치가 결과에 의존 할 때 시스템 전체의 병목 현상이 발생할 수 있습니다.
구체적인 예를 제공하기 위해 다음 스크린 샷에서 OpScript_lsysString은 장면 그래프 위치 / root / world / geo / lsys에 값 비싼 L 시스템 설명을 생성합니다. 그런 다음 노드 OpScript_lsystem은이 설명을 처리하여 트리의 그래픽 표현을 작성합니다.
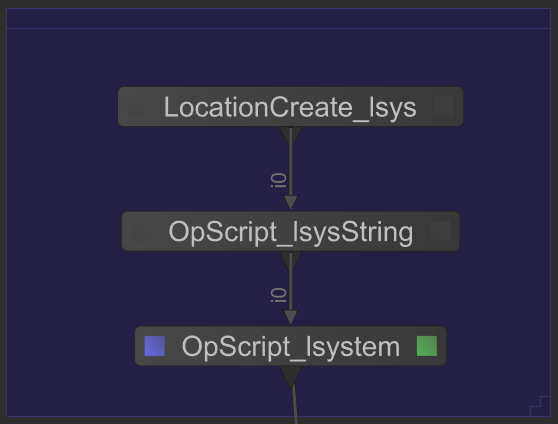
OpScript_lsystem의 작업은 OpScript_lsysString에 전적으로 의존하기 때문에 OpScript_lsysString이 / root / world / geo / lsys를 계산할 때까지 전체 장면 그래프 처리가 정지됩니다. 이 트리를 처리 할 때의 결과 처리량은 다음과 같습니다.
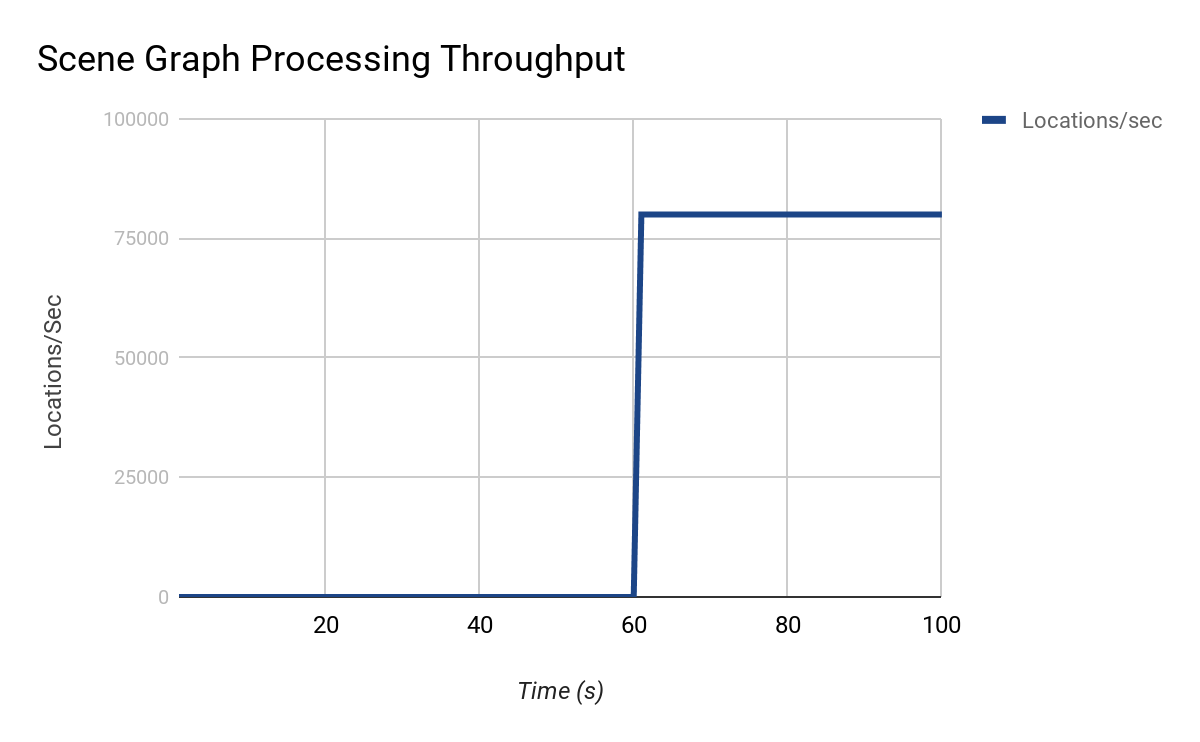
초기 검사에서 0-60 사이의 처리가 뮤텍스 또는 시리얼 코드에 의해 제한된다고 가정하는 것이 합리적 일 수 있습니다. 그러나 앞에서 설명한 바와 같이, 이것은 실제로 나머지 장면이 의존하는 매우 비용이 많이 드는 위치입니다. 이와 같은 장면 병목 현상을 해결하기 위해 어떤 옵션이 있습니까?
먼저, 함께 제공되는 Op 트리 프로파일 링 도구를 사용할 수 있습니다 Katana 3.5 현장에서 비용이 많이 드는 Op를 식별합니다. 이 정보를 사용하여 값 비싼 Ops의 성능을 최적화 할 수 있습니다. 이 작전을 최적화하는 것은 주로 그들이하는 일의 성격에 달려 있습니다. 그러나 다른 최적화 작업과 마찬가지로 먼저 최적화 대상을 식별하고 측정, 리팩터링 및 재 측정하십시오.
Op 트리에서 하나 또는 두 개의 주요 Op를 최적화하여 병목 현상을 완전히 제거 할 수 있습니다. 위의 예에서 Lua 객체 생성을 신중하게 사용하면 L 시스템 설명을 계산하는 시간이 크게 줄어든 경우입니다. 그러나 때로는 비용이 많이 드는 작업을 받아 들여야합니다. 이 경우 장면 처리 처리량을 유지하는 데 도움이되는 옵션은 무엇입니까?
다음 단계는 처리 문제 자체를 검사하는 것입니다. 장면 그래프 위치에 의해 링크되거나 색인 될 수있는 더 작은 논리적 청크로 나눌 수 있습니다. 장면 그래프 토폴로지를 효과적으로 사용하여 각 자식이 병렬로 처리 할 수있는 작업의 하위 섹션을 나타내는 병렬 처리 작업 그래프를 나타냅니다.
예를 들어 첫 1000 개의 소수를 계산해야한다고 가정 해 봅시다. / root / world / geo / data / primes 위치에서 각 프라임을 차례로 계산하여 IntAttribute로 저장하는 Op를 작성할 수 있습니다. 또는 / root / world / geo / data / primes 아래에 1000 개의 자식을 만드는 Op를 만들 수 있으며 각 자식의 위치는 주요 시리즈에 대한 인덱스 역할을합니다. 그런 어린이들에게 Op는 시리즈의 해당 시점에서 소수를 계산합니다. 이 예에서 Geolib3-MT는 장면 그래프 내에서 사용 가능한 병렬 처리를 활용하여 각 자식이 병렬로 실행되도록 예약 할 수 있습니다.
이 접근 방식의 확장은 연산 트리를 사용하여 계산 집약적 인 작업이 분할되고 결과가 병합 노드를 사용하여 정렬되는 계산 독립적 장면 그래프에 대한 병합 분기 사용에서도 제공됩니다.
마지막으로 장면 순회 패턴에 대한 지식을 활용할 수 있습니다. Geolib3-MT는 장면의 폭 넓은 첫 번째 확장을 완료하므로 계산적으로 비싼 장면 그래프 위치가있는 경우 병렬로 처리 할 수있는 다른 자식이 여러 개있는 장면 그래프 위치 아래에 배치하십시오. 그런 다음 한 위치에서 요리하는 데 시간이 오래 걸리더라도 다른 위치 (실제로 나머지 장면 그래프)가 평가되지 않습니다.
처리 용량
장면 처리량은 처리 용량에 의해 제한 될 수 있습니다. 사용 가능한 CPU 코어보다 처리 할 장면 그래프 위치가 더 많은 경우, 사용 가능한 코어의 완전한 활용 (포화) 및 처리를 기다리는 장면 그래프 위치의 백 로그가 예상됩니다. 일반적으로 코어를 더 추가하면 장면 그래프 처리 시간이 단축됩니다.
반대로, 가용 컴퓨팅 리소스가 새로운 위치가 알려진 것보다 빠르게 장면 그래프 위치를 처리 할 수 있거나 장면에 단순히 충분히 크지 않은 경우 (Op 트리의 Ops 처리에 따라 "충분히 큰"경우) 각 장면 그래프 위치에서) 모든 코어를 활용하기위한 장면 그래프 위치 수 해당 코어를 완전히 활용하는 데 사용할 수있는 코어 수를 줄이는 것이 좋습니다. 성능 관점에서 볼 때 이는 L2 / L3 캐시 성능을 잠재적으로 향상시킬 수있는 CPU 고정 전략과 결합 할 때 유용 할 수 있습니다.
뮤텍스 및 기타 동기화 프리미티브의 간접 사용 식별
코드의 직렬화 된 실행을 강제하는 뮤텍스 및 기타 동기화 프리미티브는 장면 그래프 평가 성능에 상당한 영향을 줄 수 있습니다. 자체 코드에서 뮤텍스를 식별하는 것이 간단 할 수 있지만 타사 코드 및 라이브러리에서 더 문제가 될 수 있습니다.
씬의 Ops가 뮤텍스로 싸인 코드를 간접적으로 호출 할 수있는 증상은 다음과 같습니다.
- 장면 처리에 사용할 수있는 스레드 / 코어 수를 늘리면 장면 그래프 확장 및 첫 번째 픽셀까지의 시간이 줄어들지 않고 증가합니다.
- 스레드 안전하지 않은 Op를 나타내는 렌더링 로그의 메시지가 호출되었습니다.
- 장면 처리에는 여러 스레드 / 코어를 사용할 수 있지만 실제로는 하나 또는 두 개의 코어 만 사용됩니다.
오가와까지 Alembic HDF5
구체적인 예를 제공하기 위해 Alembic 캐시는 HDF5와 병렬 장면 탐색을 지원하도록 설계된 최신 Ogawa 형식의 두 가지 형식으로 저장할 수 있습니다. 메시지가 인쇄되지 않는 동안 Render Log HDF5 형식의 캐시를 읽을 때 장면 통과 시간이 현저히 느려지고 더 많은 스레드가 추가되면 성능이 저하 될 수 있습니다. 약 140k 개의 위치가있는 테스트 장면에서 기존 HDF5 캐시를 Ogawa로 변환하면 처리 할 수있는 32 개의 코어 작업 풀을 사용하여 장면 통과 시간이 26.2 초에서 3.9 초로 단축되었습니다.
Alembic 라이브러리는 Alembic 파일을 HDF5에서 agawaconvert라고하는 Ogawa로 변환하는 유틸리티를 제공합니다. 이 유틸리티는 소스에서 빌드해야합니다. 이 출처는 여기리포지토리의 루트에 지침이 있습니다.
일단 빌드되면 abcconvert는 다음과 같이 명령 행에서 사용될 수 있습니다.
- cd / path / to / build / directory
- abcconvert -toOgawa -in <입력 파일> <출력 파일>
입력 파일이 이미 Ogawa 형식 인 경우 abcconvert는 아무 작업도 수행하지 않습니다.
도움이되지 않은 죄송합니다
왜 도움이되지 않습니까? (해당되는 모든 것을 체크하세요)
의견을 보내 주셔서 감사합니다.
찾고있는 것을 찾을 수 없거나 워크 플로에 대한 질문이있는 경우 시도해보십시오 파운드리 지원.
학습 내용을 개선 할 수있는 방법에 대한 의견이 있으시면 아래 버튼을 사용하여 설명서 팀에 이메일을 보내십시오.
의견을 보내 주셔서 감사합니다.