Creating a Data Set for Training
Video: Creating Mattes Using CopyCat in Nuke
A CopyCat data set is a number of image pairs used to train a network to perform a specific task. Image pairs consist of one Input image and one Ground Truth image, before and after the effect is applied. The network is attempting to learn how to create the Ground Truth from the Input image.
Note: The Input and Ground Truth image pairs must be the same format size.
CopyCat can ingest sequential formats, such as .jpg and .exr, and container formats, such as .mov and .mxf, but the set up is slightly different in each case.
Sequential Format Data Sets
Sequences of .jpg and .exr files are the simplest data sets to create because they're already broken down into the individual frames required for training. This example shows a data set you could use to teach a network to apply a matte, but the principle is the same for clean up, deblurring, or any other manual work.
- Play through your sequence and select a number of frames to use for the data set.
- Create a Read node for each frame selected and set the File control to point to the required frame number. For example:
- Create an AppendClip node and connect all the Read nodes.
- Connect the AppendClip node to the CopyCat node's Input pipe.
- Using the same frames, roto out the masks for the Ground Truth.
See Using RotoPaint for more information on Roto and RotoPaint. - Create a Read node for each of the masks and set the File control to point to the required frame number. For example:
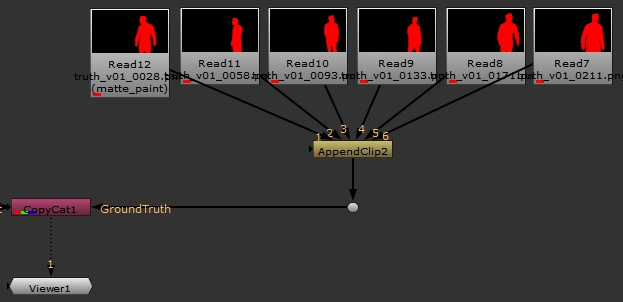
- Create an AppendClip node and connect all the Read nodes.
- Connect the AppendClip node to the CopyCat node's Ground Truth pipe.
- Proceed to Training and Monitoring the Network for more details on CopyCat settings and training.
A diverse selection of images tends to produce the best results and the more frames you use, the better the results are likely to be. For example, if you're training a network to mask an object, try to pick frames that represent a wide variety of mask shapes.
../assets/input/input_v01_0211.png
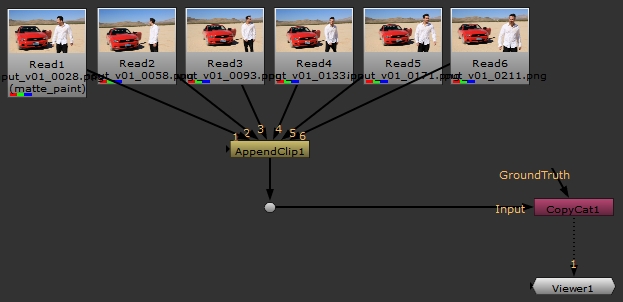
Note: In this example, the alpha channel was written to disk separately, but CopyCat can read the alpha from the Roto shapes in the Node Graph.
../assets/groundtruth/truth_v01_0211.png
Warning: Ensure that your Ground Truth images are connected to the AppendClip node in the same order as your Input images. Image pairs that don't match affect the quality of the resulting model.
Container Format Data Sets
Container formats like .mov and .mxf files require a bit more work to separate out the individual frames required for training. This example shows a data set you could use to teach a network to apply a matte, but the principle is the same for clean up, deblurring, or any other manual work.
- Play through your sequence and select a number of frames to use for the data set.
- Create a Read node and set the File control to point to the full sequence. For example:
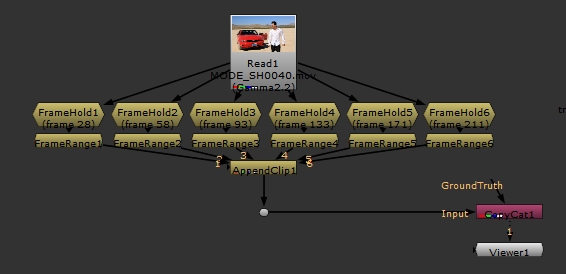
- Create a FrameHold and FrameRange node for each frame selected in the data set.
- Set each FrameHold node's first frame control to the required frame and the FrameRange node's frame range control to 1-1.
- Create an AppendClip node and connect all the FrameRange nodes.
- Connect the AppendClip node to the CopyCat node's Input pipe.
- Using the same frames, roto out the masks for the Ground Truth and write the alpha channel to disk.
See Using RotoPaint for more information on Roto and RotoPaint. - Create a Read node for each of the masks and set the File control to point to the required frame number. For example:
- Create an AppendClip node and connect all the Read nodes.
-
Warning: Ensure that your Ground Truth images are connected to the AppendClip node in the same order as your Input images. Image pairs that don't match affect the quality of the resulting model.
- Connect the AppendClip node to the CopyCat node's Ground Truth pipe.
A diverse selection of images tends to produce the best results and the more frames you use, the better the results are likely to be. For example, if you're training a network to mask an object, try to pick frames that represent a wide variety of mask shapes.
../assets/input/input_v01.mov
Note: The FrameRange nodes ensure that only 1 frame is ingested by CopyCat per Read node, the frame specified by the FrameHold node.
../assets/groundtruth/truth_v01_0211.png
Training and Monitoring the Network
Train your network using the data set to replicate the desired effect.
Applying and Improving the Results
Apply a trained network to a sequence using the Inference node.