组成并发友好场景
了解场景吞吐量以及如何识别瓶颈
在Geolib3-MT中,系统吞吐量定义为每秒处理的场景图位置的数量。在处理给定的场景图时,瞬间的目的是维持或提高Geolib3-MT的处理吞吐量。
位置瓶颈
在典型场景中,某些场景图位置的计算时间比其他场景花费的时间更长,这是场景图处理的正常行为和预期行为。但是,当后续位置取决于其结果时,这些计算昂贵的位置可能成为系统范围的瓶颈。
为了提供一个具体的示例,在下面的屏幕快照中,OpScript_lsysString在场景图位置/ root / world / geo / lsys上生成了昂贵的L系统描述。然后,节点OpScript_lsystem处理该描述以构建树的图形表示。
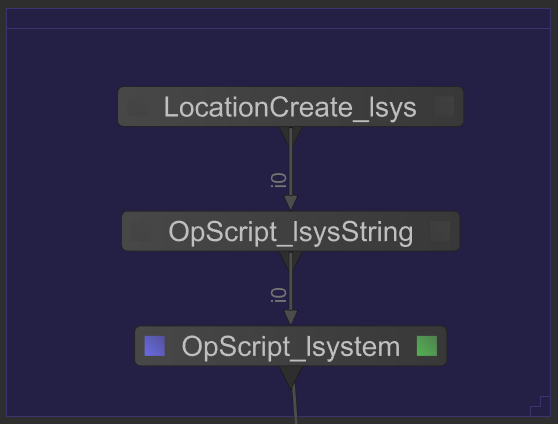
由于OpScript_lsystem的工作完全取决于OpScript_lsysString,因此整个场景图的处理将暂停,直到由OpScript_lsysString计算/ root / world / geo / lsys为止。处理此树时产生的吞吐量大约为:
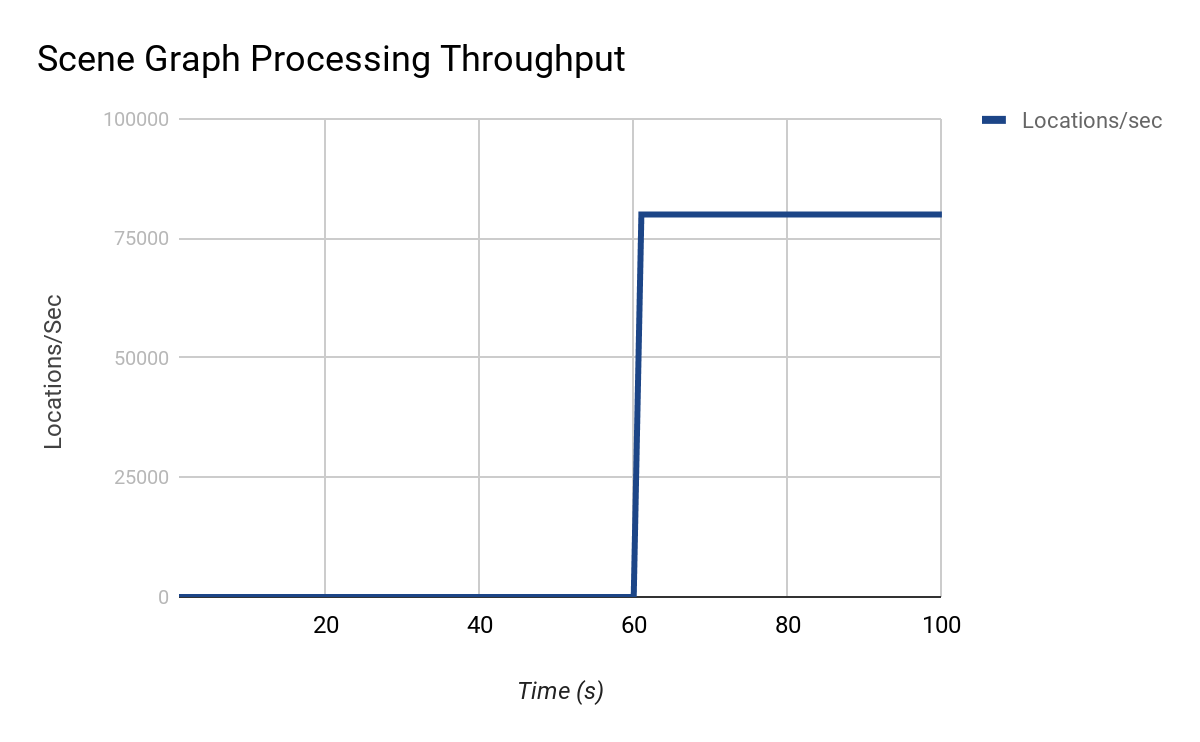
初步检查时,可以合理地假设0-60秒之间的处理受互斥锁或串行代码的限制。但是,如前所述,这实际上是场景其余部分所依赖的非常昂贵的位置。存在哪些选项可以解决这样的场景瓶颈?
首先,我们可以使用随附的Op树分析工具Katana 3.5识别现场昂贵的行动。利用这些信息,我们可以寻求优化那些昂贵的Ops的性能。优化这些Ops在很大程度上取决于他们所从事的工作的性质。但与任何优化任务一样,首先要确定一个优化目标,进行度量,重构和重新度量。
仅通过优化Op树中的一两个关键Op,就有可能完全消除瓶颈。在上面的示例中就是这种情况,其中认真使用Lua对象创建大大减少了计算L系统描述的时间。但是,有时我们必须接受操作成本高昂;在这种情况下,存在哪些选项可以帮助维持场景处理吞吐量?
下一步是检查处理问题本身,是否可以将其分解为较小的逻辑块,这些块可以由场景图位置链接或索引。有效地使用场景图拓扑来表示并行处理任务图,其中每个子代代表可以并行处理的工作的一部分。
例如,假设我们需要计算前1000个素数。我们可以创建一个Op,在/ root / world / geo / data / primes位置依次计算每个素数,并将它们存储为IntAttribute。或者,我们可以创建一个Op,在/ root / world / geo / data / primes下创建1000个子代,每个子代的位置作为素数系列的索引。然后,对于那些孩子,运算将计算系列中该点的素数。在此示例中,Geolib3-MT能够利用场景图中可用的并行性来安排每个孩子并行运行。
在“使用合并”分支中还为该计算独立的场景图提供了对该方法的扩展,其中使用Op树分解了计算密集型工作,并使用“合并”节点整理了结果。
最后,您可以利用场景遍历模式的知识来发挥自己的优势。Geolib3-MT完成了场景的广度优先扩展,因此,如果存在计算上昂贵的场景图位置,请考虑将其放置在具有许多其他子代的场景图位置下,这些子代也可以并行处理。这样,虽然一个位置的烹饪时间可能会更长,但它不会阻止其他位置(实际上是场景图的其余部分)的评估。
处理能力
场景吞吐量可以受处理能力的限制。如果要处理的场景图位置多于可用的CPU内核,我们希望可以看到可用内核的完全利用率(饱和)以及等待处理的场景图位置的积压。通常,添加更多核心应有助于减少场景图处理时间。
相反,如果可用的计算资源能够比已知的新位置更快地处理场景图位置,或者,如果场景根本不包含足够大的空间(“足够大”还取决于Op树中的Ops正在执行的处理每个场景图位置处的场景图位置数),以保持所有内核被利用,您可能会受益于减少可充分利用这些内核的可用内核数。从性能的角度来看,当与CPU固定策略结合使用时,这可能是有益的,它可以潜在地提高L2 / L3缓存性能。
识别间接使用互斥对象和其他同步基元
强制执行代码的序列化执行的互斥体和其他同步原语可能会对场景图评估性能产生重大不利影响。虽然在您自己的代码中识别互斥锁可能很简单,但在第三方代码和库中可能会出现更多问题。
场景中的Ops可能间接调用包装在互斥体或关键部分中的代码的症状包括:
- 可用于场景处理的线程/核数的增加,而不是减少了场景图扩展和到达第一个像素的时间,而不是减少。
- 渲染日志中的消息表明已调用了线程不安全的Op。
- 多个线程/内核可用于场景处理,但实际仅使用一个或两个内核。
Alembic HDF5至小川
为了提供一个具体的示例,可以将Alembic缓存以HDF5和较新的Ogawa格式两种格式存储,该格式旨在支持并行场景遍历。虽然没有消息打印到Render Log读取HDF5格式的缓存时,场景遍历时间明显变慢,并且当添加更多线程时性能甚至可能下降。在一个大约有14万个位置的测试场景中,将现有的HDF5缓存转换为Ogawa可以看到场景遍历时间从26.2s减少到3.9s,并且具有32个核心任务池可供处理。
Alembic库提供了一个实用程序,可将Alembic文件从HDF5转换为Ogawa,称为abcconvert。该实用程序必须从源代码构建。可以在以下位置找到此来源这里,并在存储库的根目录中包含说明。
构建完成后,可以从命令行按如下方式使用abcconvert:
- cd /路径/到/构建/目录
- abcconvert -toOgawa -in <输入文件> <输出文件>
如果输入文件已经是Ogawa格式,则abcconvert不执行任何操作。