Geolib3-MT分析
Geolib3-MT添加了一个新的渲染类型,称为Preview Render with Profiling,旨在帮助跟踪场景遍历中的性能问题。这执行正常Preview Render,还捕获有关运行哪些Ops,Op用于烹饪位置的CPU量以及用于属性和Lua脚本的内存量的信息。
带有分析的预览渲染器在两个位置输出分析数据:
- 总结报告Render Log,其中包含使用的总CPU时间和内存,以及十个最昂贵的操作。
- 写入磁盘的JSON文件,其中包含原始分析数据。
使用性能分析启动预览渲染
一种Preview Render with Profiling可以从与任何其他渲染相同的菜单中启动:
- 右键单击要渲染的节点。
- 请点击Preview Render with Profiling从菜单中。
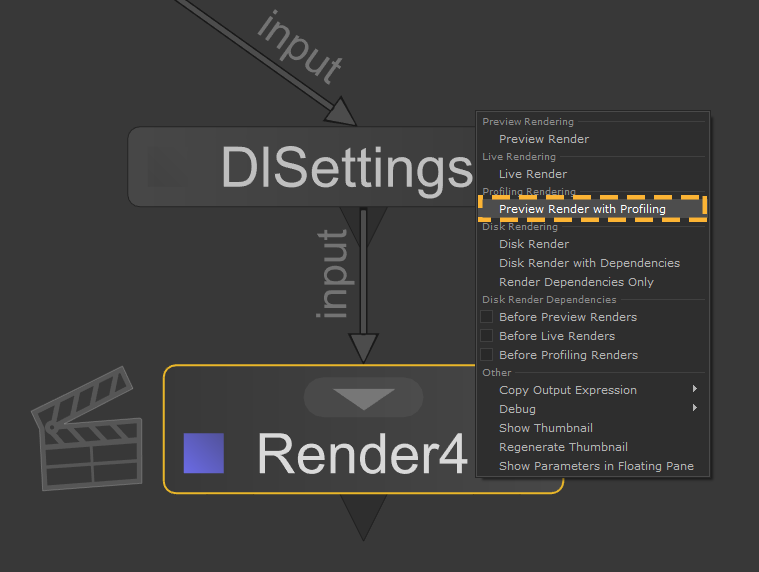
此选项可用于任何已经支持Preview Render,并且渲染器不需要任何其他工作。如果渲染器实现了finalize() Geolib3-MT运行时的方法,这些分析报告将在运行时完成时创建;否则,报告将在渲染完成时写入。
在执行过程中捕获分析数据的开销Preview Render with Profiling很小,并且与正常情况相比不会出现明显的减速Preview Render。
捕获了什么信息?
一种Preview Render with Profiling为场景遍历期间执行的每个Op捕获以下信息:
- 的name, type和numerical ID的。
每个Op都有名称,类型和唯一的数字ID。例如, OpScript Op可能有名字op74,类型OpScript.Lua;和ID 77。注意: 的name和ID不需要关联。
- 的name和type的Katana产生Op的节点。
如果操作是由操作员直接生成的Katana节点name和type该节点的记录。在隐式创建Op的情况下,节点名称将等于_NoName_并且类型将等于_NoType_。例如,这种情况发生在MaterialFilenameResolve这些操作是在需要解析文件名时隐式创建的,因此不需要Katana节点被标识为创建者。注意: 如果sceneTraversal.opTreeOptimizations已启用且操作链已折叠,节点name和type将替换为从链中生成的字符串。如果链长t,由类型的Ops组成opType ,在哪里Op k被称为oķ并由Katana节点名为n ķ,字符串的一般形式为:但是,不能保证此字符串的格式保持固定。
- 的total CPU time Op在烹饪场所度过。
每个操作员都会在很多地方做饭,并且花费在所有场景遍历线程上的时间会累积起来。并行遍历场景时,CPU时间与场景遍历线程数成比例。如果不是这种情况,则可能在所讨论的Op上游存在线程不安全的Op。 - 的memory footprint该操作。
每个Op必须分配内存来烹饪位置,并且每个Op的总内存是聚合的。
当前,记录了以下分配:
- 的分配FnAttribute库,用于存储煮熟位置的属性。
- 的分配Lua执行OpScript时的解释器。
- 进行存储分配CookResults在缓存中。
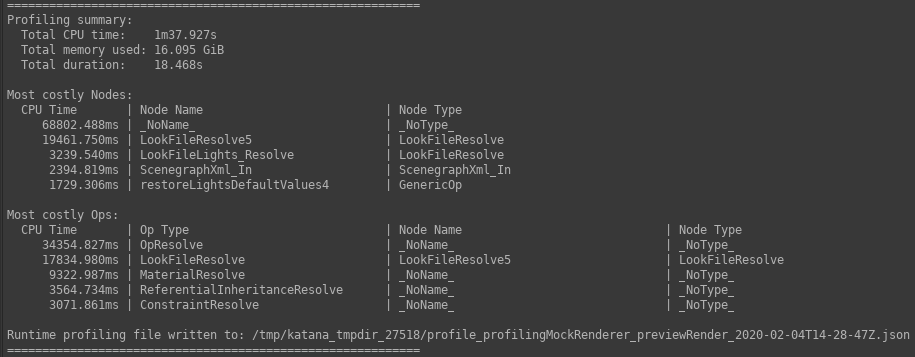
分析摘要报告
摘要报告将写入Render Log完成后Preview Render with Profiling。该报告旨在提供概要文件数据的高级概述,并包含:
- 所有操作的总CPU时间。
- 所有操作的总内存占用量。
- CPU时间最慢的五个操作。
|
|
| 示例的相关部分Render Log. |
分析JSON文件
除了摘要报告之外,还将包含原始概要分析数据的JSON文件写入磁盘。写入的目录由--profiling-dir命令行参数;如果未设置,它将被写入到临时目录中。 Katana会议。如果该目录不存在,只要文件系统权限允许,它将被创建。文件名采用以下格式:
profile_ <renderer> _previewRender_ <datetime> .json
哪里:
- <renderer>是渲染插件的名称,例如dl表示3Delight;
- <datetime>是开始渲染后的ISO8601时间戳。
该文件包含一个具有以下属性的JSON对象:
|
属性 |
类型 |
描述 |
例 |
|
时间戳记 |
串 |
写入配置文件的ISO8601时间戳。 |
2019-10-11T09:37:06Z |
|
渲染器 |
串 |
渲染插件的名称。 |
dl |
|
renderMethodName |
串 |
渲染方法的名称;目前总是previewRender。 |
PreviewRender |
|
环境 |
宾语 |
包含各种环境变量的值的对象,包括:
|
{ “ KATANA_RELEASE”:“ 3.5v1”, “ KATANA_ROOT”:/opt/foundry/katana3.5v1”, “ KATANA_RESOURCES”:“ <未设置>” } |
|
profileMode |
串 |
配置文件模式的名称;目前总是basic。 |
基本的 |
|
行动 |
数组 |
描述每个Op消耗的资源的对象数组。 |
见下表 |
|
numOps |
数 |
Ops数组的长度。 |
78 |
|
wallTime |
数 |
从渲染开始到写入配置文件之间的时间,以秒为单位;如果渲染器实现finalize(),这等于场景遍历时间。 |
46.85064 |
|
cpuTime |
数 |
所有操作的CPU时间总和,以秒为单位。 |
91.39238 |
|
使用的内存 |
数 |
所有操作的内存占用总和,以字节为单位。 |
10728607911 |
ops属性包含以下格式的对象数组,每个对象用于场景遍历期间执行的每个Op。
|
属性 |
类型 |
描述 |
例 |
|
opId |
数 |
Op的唯一整数标识符。 |
23 |
|
opName |
串 |
作品的唯一名称。 |
op223 |
|
opType |
串 |
运营类型。 |
属性集 |
|
nodeName |
串 |
的名称Katana负责创建此Op的节点,或_NoName_如果Op是隐式创建的。 |
RenderSettings_SetSamples |
|
nodeType |
串 |
的类型Katana负责创建此Op的节点,或_NoType_如果Op是隐式创建的。 |
渲染设置 |
|
cpuTime |
数 |
该操作员花费在所有线程上的烹饪位置的总时间(以秒为单位)。 |
0.54512136 |
|
使用的内存 |
数 |
如上定义,此Op在烹饪位置时使用的总内存量(以字节为单位)。 |
185378321 |
分析配置文件结果
包含Python 2.7脚本,以各种方式对结果进行排序和分组。该脚本可以在这里找到:
$ KATANA_ROOT / extras / Profiling / analyzeProfilingRenderResults.py
您可以从命令行按如下所示调用此Python脚本:
cd $ KATANA_ROOT / extras /分析
python analyticsProfilingRenderResults.py /path/to/results/file.json <选项>
以下命令行选项可用:
|
- 救命 |
显示帮助文本并退出。 |
|
--sort-by FIELDNAME |
按FIELDNAME对结果进行排序,其中FIELDNAME是JSON属性名称opId,opName,opType,nodeName,nodeType,cpuTime或memoryUsed之一。 |
|
--reverse,-r |
以相反的顺序对结果进行排序。 |
|
--group-by FIELDNAME |
将结果按FIELDNAME分组,其中FIELDNAME是JSON属性名称opId,opName,opType,nodeName,nodeType,cpuTime或memoryUsed之一。 |
|
-人类可读的-h |
打印内存以人类可读的单位总计(即KiB,MiB等),而不是字节。 |
|
--limit LIMIT,-l LIMIT |
分组和排序后,将输出限制为前LIMIT行。 |
|
-栏栏 |
仅输出指定的列,其中COLUMNS是JSON属性名称opId,opName,opType,nodeName,nodeType,cpuTime或memoryUsed的逗号分隔列表。 |
该脚本将ASCII结果表输出到stdout,根据要求进行分组和排序。如果--sort-by未设置,结果将按以下顺序排序opId。如果--group-by未设置,将不会进行分组。
注意: 分组时nodeName,所有结果名称_NoName_将分组在一起。情况也是如此nodeType。
以下命令行选项组合可能对入门很有帮助:
|
--group-by opType --sort-by cpuTime |
找出哪些Op类型最占用CPU。 |
|
--group-by nodeName --sort-by cpuTime |
找出哪个Katana节点最消耗CPU。 |
|
--group-by nodeType-排序内存 |
找出哪个Katana节点类型占最大的内存占用。 |