Share the Load with Distributed CopyCat Training
CopyCat can share the training load across multiple machines, with a familiar interface, so that distributing training feels just like distributing rendering using standard render farm applications such as OpenCue.
Offloading the training onto different machines also means that you can continue working when CopyCat is training models in the background.
Note: Distributed CopyCat training is qualified on Nuke 14.1 and 15.0.
Distributed CopyCat training via OpenCue has been validated internally using 14.1. We expect it would work using 15.0 but this has not been tested.
As an artist, you work as normal on your workstation and the render manager handles the distribution of training tasks to the available workers. The image shows a typical distributed training set up using a render manager to distribute the training load.
Note: You must also install Nuke on the worker machines for distributed training to operate as expected.
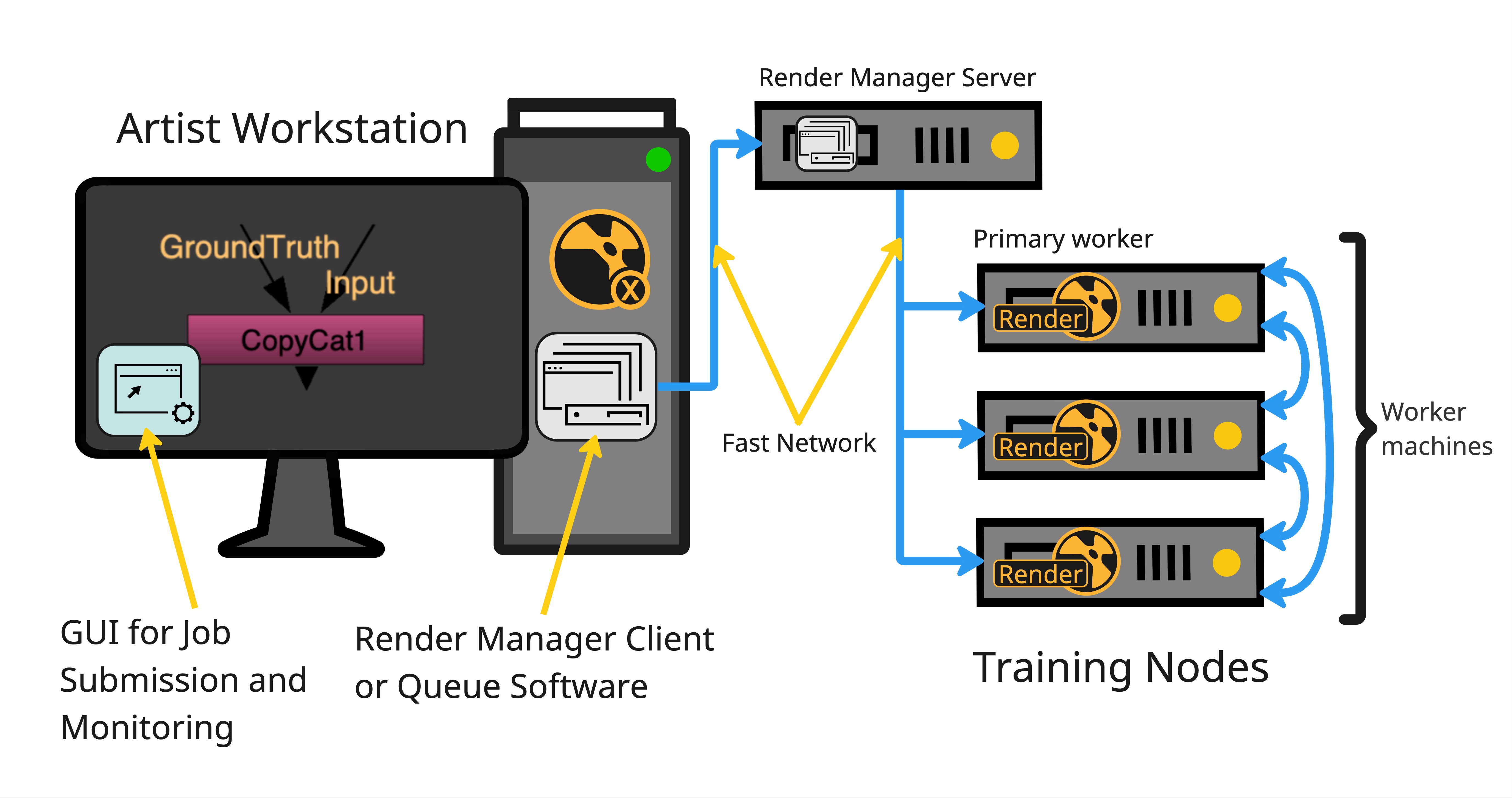
Note: CopyCat can train using Nuke Render Licences on distributed machines
Distributed Training in CopyCat is controlled through the following environment variables:
- COPYCAT_MAIN_ADDR: the main address. Process 0 runs on this IP address and only this process saves the contact sheets, graphs, and training model checkpoints.
- COPYCAT_MAIN_PORT: the main port for process 0.
- COPYCAT_RANK: the current process rank relative to other processes. COPYCAT_RANK must be < COPYCAT_WORLD_SIZE.
- COPYCAT_WORLD_SIZE: the total number of processes between which training is distributed.
For example, if COPYCAT_WORLD_SIZE = 4, four processes are launched on the same Nuke script and CopyCat node with the same COPYCAT_MAIN_ADDR and COPYCAT_MAIN_PORT, and with COPYCAT_RANK being 0, 1, 2, and 3. - COPYCAT_SYNC_INTERVAL (optional): the interval at which gradients are shared between processes. By default, synchronization happens every 1 step. You can increase this value for better network latency.
- COPYCAT_LOCAL_ADDR (optional/required for speed): the IP address of the local machine on which you are running distributed training. COPYCAT_LOCAL_ADDR can be used to make sure you are running distributed training on fast network lines.
Note: If you omit one of the four required environment variables, CopyCat runs in non-distributed mode and Nuke is locked until training completes or is stopped.
Manual Distributed Training Example
Set up distributed training from the command line.
Automated Distributed Training Example
Set up distributed training using a render manager.
Manage and Monitor Training in CopyCat
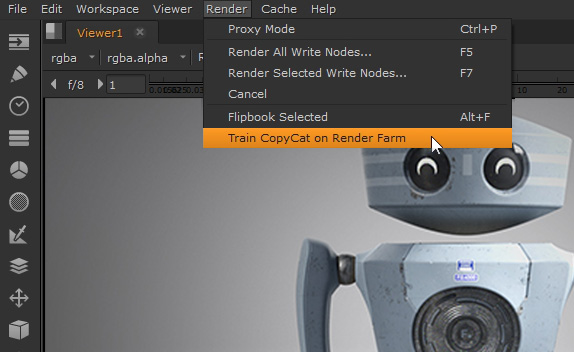
When distributed training is set up and working correctly, you can start training in Nuke's menu bar, rather than in CopyCat's Properties panel. Custom menu items can be added using a Python script, an example of which you can find on the Automated Distributed Training Example page. In this example, we're using OpenCue's CueGUI application to manage training runs from within Nuke and we've added a Train CopyCat on Render Farm function to Nuke's Render menu.
Tip: If you train CopyCat models without distributed training, Nuke is locked until training completes or is stopped.
- Go to Render > Train CopyCat on Render Farm to start a training run.
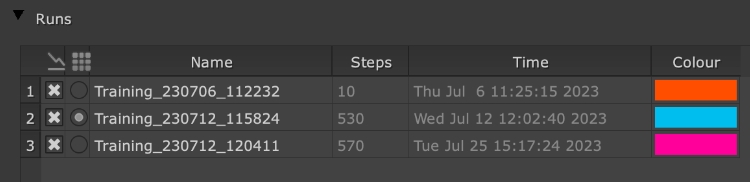
- Each run is shown in the Graph dropdown and Contact Sheet dropdown by default, but you can toggle off and on the visibility using the
 show graph and
show graph and  show contact sheet radio buttons for each run.
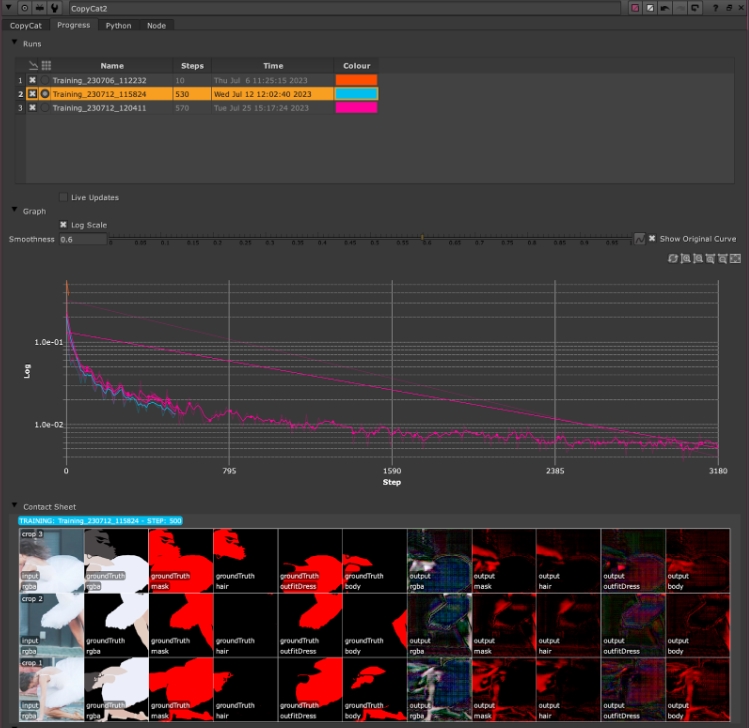
show contact sheet radio buttons for each run. - If you want to see live updates, turn on Live Updates under the Runs table. The Graph information is not updated by default to save unnecessary network polling.
Note: You won't see this option if you haven't added a custom menu item using the copycatExample.py script.
A new run is added to the CopyCat Progress tab under Runs.
Optimizing Distributed Training: How Many Machines Should You Use?
Determining the optimal number of machines for distributed training can be complex. However, here's a guide to help you make an informed decision.
Tip: Distributed training scales effectively when each GPU is heavily utilized. In simpler terms, the more work each GPU has, the better the performance when using multiple GPUs.
Factors Influencing Scalability
Batch Size
• In distributed training, the batch is divided evenly among the GPUs. For instance, with a batch size of 8 on 4 GPUs, each GPU processes 2 crops per step.
• A larger batch size means more work for each GPU, leading to better scalability.
Crop Size & Model Size
• Larger crop or model sizes mean more computations per GPU per step, enhancing the scalability when using multiple GPUs.
GPU Specifications
• High-end GPUs can process the same batch faster and with less utilization compared to lower-end GPUs. Thus, with top-tier GPUs, you might not see significant benefits from scaling unless you're also increasing batch or crop sizes.
Examples:
Scenario A
• Batch Size: 12
• Crop Size: 256
• Model Size: Medium
• GPU Spec: Low
• Recommendation: Using four GPUs might double your training speed.
Scenario B
• Batch Size: 8
• Crop Size: 128
• Model Size: Small
• GPU Spec: High
Recommendation: There might be minimal benefit in using more than one GPU.
Scenario C
• Batch Size: 128
• Crop Size: 256
• Model Size: Large
• GPU Spec: High
Recommendation: Deploying up to 8 GPUs could potentially octuple your training speed.
In conclusion, while there's no one-size-fits-all answer, considering the above factors can guide you in optimizing your distributed training setup.