Designing Node Graphs for Optimal Performance
Prune locations as early as possible
The Prune node is used to remove objects from the scene. Given the processing model used by Geolib3-MT, the sooner unneeded scene graph locations/objects are pruned from the scene, the less work will be required from both downstream Ops and Geolib3-MT itself. In this respect, Prune can be thought of as providing a filtering operation, reducing the size of the scene graph that must be processed by downstream Ops.
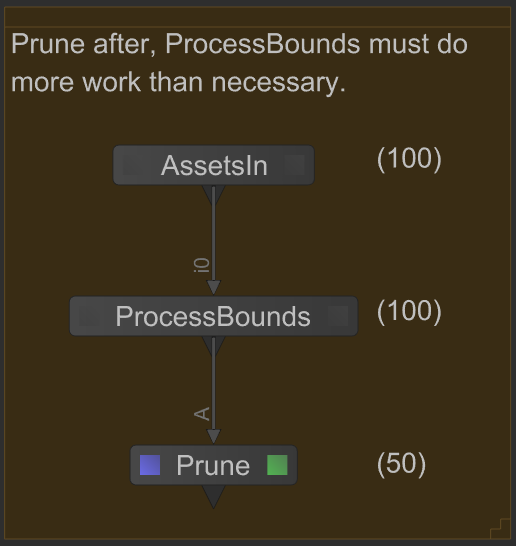
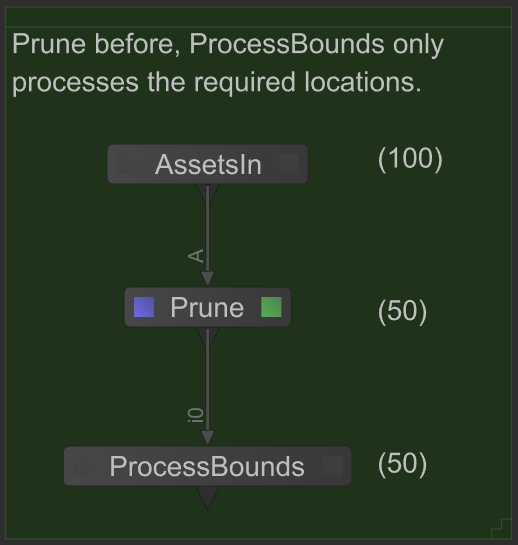
In the following example, assets are loaded by the AssetsIn node producing a scene graph of 100 locations, bounding boxes are calculated by the ProcessBounds Op on all 100 locations and then unneeded scene graph locations for this shot are then pruned from the scene. However, if the Prune node is placed closer to the AssetsIn node, the scene graph processed by ProcessBounds will be half the size. This directly translates to both memory and processing cost savings.
Summary
Prune scene graph objects/locations as early as possible. Doing so will reduce the number of locations downstream Ops must process which corresponds to a reduction in both memory and scene processing time.
Understand parallel scene processing dimensions
Geolib3-MT’s scene graph processing system searches for computationally independent tasks which can be evaluated in parallel. Broadly speaking, there are two dimensions of parallelism Geolib3-MT will look to exploit.
Scene Graph Parallelism
In a deferred/lazily evaluated scene graph such as Katana, a scene graph contains potential work. It is “potential” because we only learn of it as a scene graph location and its children become known through expansion.
Each child of a scene graph location represents a computationally independent task, depending only on its parent location. That is, once a scene graph location has been computed, all of its children can be computed in parallel.
Op Tree Parallelism
Sub sections of the Op tree can be processed in parallel. In doing so Geolib3-MT fully expands the scene at the sub section of the Op tree it’s processing. Some ops are naturally parallelizable, such as source Ops (i.e. those Ops with no inputs). Some constructs are also naturally parallelizable, such as Merge Ops, in which each op tree branch is independently computable.
Summary
Parallelism exists in two dimensions: the scene graph (by sibling) and op tree (in a number of constructs). Exploit parallelism in both dimensions to provide Geolib3-MT with the maximum backlog of known computationally independent tasks to process.
Use Merge branches for computationally independent scene graphs
Each branch of a Katana node graph can be thought of as producing an independent scene graph, which are combined through the use of a Merge node.
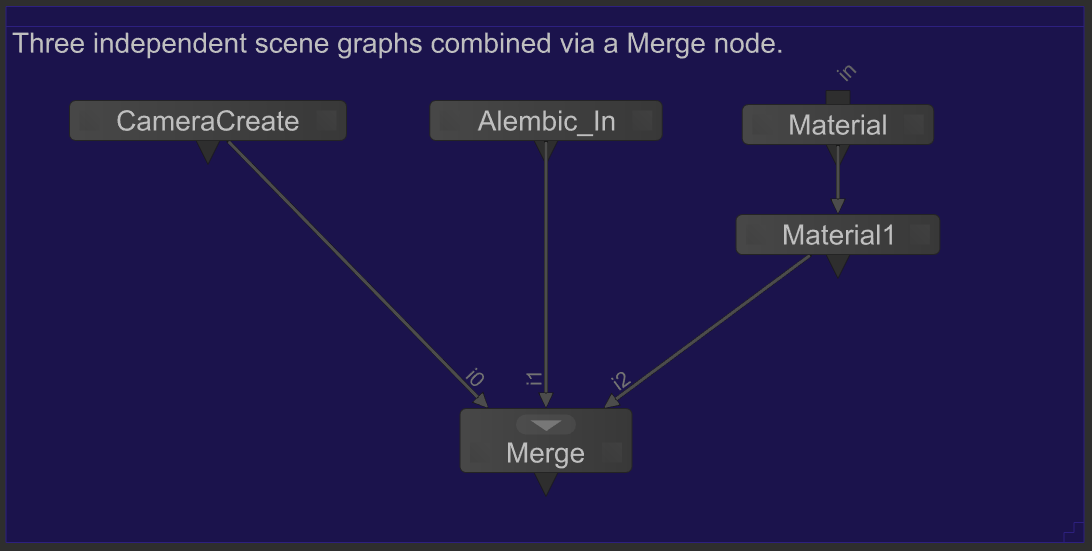
As each branch of the Merge node represents a computationally independent scene graph, Geolib3-MT will exploit this fact to expand each branch in parallel. If this behaviour is not desired, it can be disabled in the RenderSettings node. To benefit from this parallel expansion of Op tree branches there are a number of things to consider:
Consider your scene graph not as one large scene graph but multiple smaller scene graphs, each produced by one or more connected Ops.
Consider the data dependencies that exist in your scene graphs and the nodes an Ops responsible for producing them. Are there opportunities to refactor your node graph to take advantage of the parallel processing available from multiple independent branches?
Identify CPU-bound operations that must operate on multiple locations. Whilst Geolib3-MT will exploit parallelism available within the scene graph itself (by processing independent locations in parallel), CPU bound operations could also be evaluated in parallel by duplicating CPU bound nodes and ops. For example:
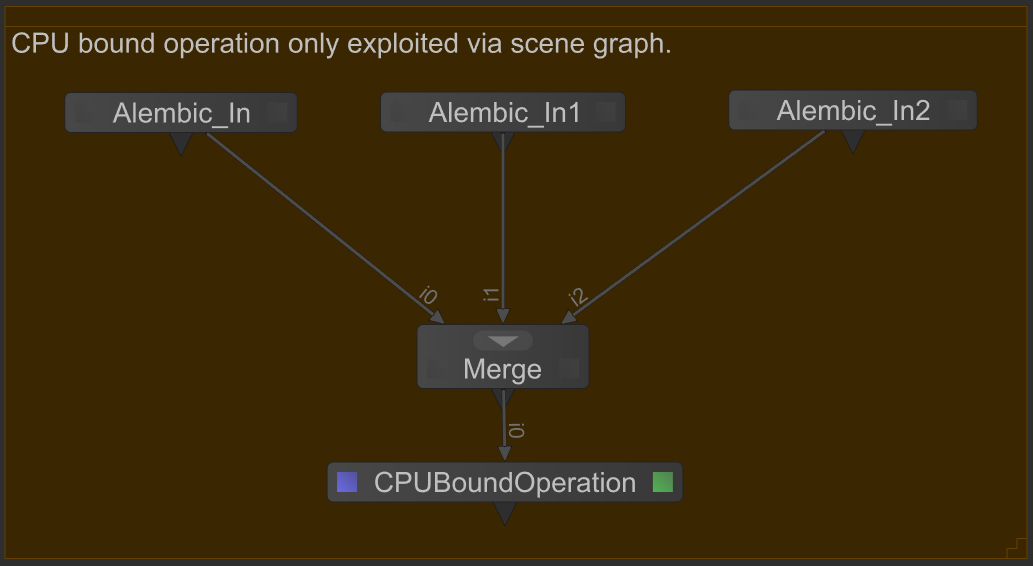
In this example, whilst the three scene graphs produced by the Alembic_In nodes will be generated in parallel, the parallelism available to the CPUBoundOperation node is limited to the scene graph only. Compare this node graph with the following refactored version in which the CPUBoundOperation is placed within each branch,
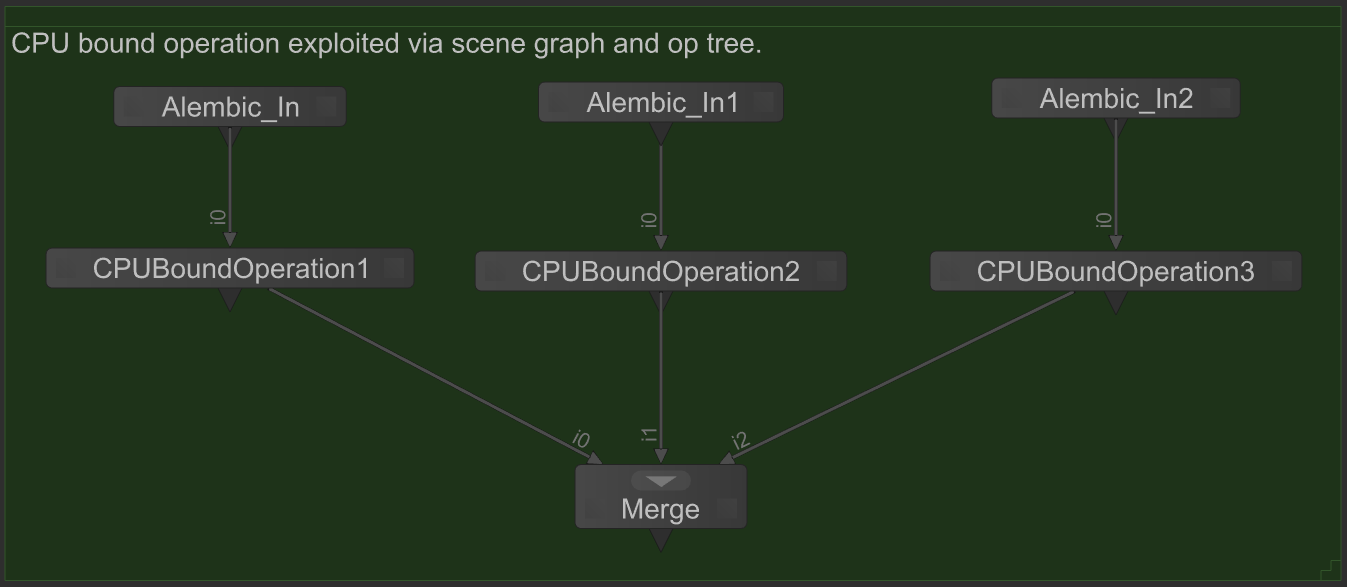
Here the CPUBoundOperation can take advantage of parallelism in both dimensions (scene graph and Op tree). For more information on available parallelism see Understand parallel scene processing dimensions.
Summary
Consider your scene graph not as one large scene graph but multiple smaller scene graphs, each produced by one or more connected ops. Refactor your node graph to exploit the parallelism available in both the scene graph and op tree. Profile and measure your results.
Place chains of collapsible Nodes/Ops together
In order to process a scene graph location at a particular Op, Geolib3-MT must perform a number of steps, including but not limited to:
Ensuring the location’s dependencies (parent location and the location it will inherit its attributes from) have also been evaluated.
Memory has been allocated to store the results of processing the scene graph location.
Any inherited scene graph attributes have been applied prior to cooking the location.
Evaluate the actual location using the Op’s cook function.
Whilst this process is efficient, it is not cost-free. Checking dependencies requires checking a central cook result store, memory allocation requires a (potential) system call and the cook call incurs a small overhead to call the function (even if the cook() call doesn’t mutate the scene graph).
With this in mind, anything that can be done to reduce the number of cooks has the potential to improve scene graph processing time and reduce memory usage.
Geolib3-MT’s new Op tree optimization feature performs a preprocessing step to analyze the topology of the Op tree. One such optimization is the collapsing of chains of Ops of the same type. For example, a series of four AttributeSet Ops acting on the same set of locations may be collapsed into a single AttributeSet acting on that set of locations. This reduces the number of cook results in the caching subsystem, thus reducing the memory footprint of scene traversal.
Summary
If your scene contains multiple Ops of the same type, acting on the same set of locations, consider rearranging them to form a chain.